mdxplain Tutorial: Introduction to Conformational Analysis with mdxplain
Introduction
Proteins are dynamic molecules that sample multiple conformational states during their lifespan. Understanding which conformations exist and what distinguishes them at the molecular level is crucial for comprehending protein mechanisms. The challenge in analyzing molecular dynamics (MD) trajectories lies in extracting biologically meaningful conformational states from thousands of simulation frames. Traditional approaches often require manual selection of collective variables or a priori knowledge of relevant structural features.
This tutorial demonstrates a workflow build with mdxplain an automated pipeline builder that can be used to identify distinct conformational states and determines the characteristics (here specific residue-residue contacts) that characterize each state. The approach combines machine learning techniques with structural biology principles to transform high-dimensional trajectory data into interpretable biological insights.
Methodology Overview
The pipeline addresses key challenges in conformational analysis:
Feature Engineering: Convert atomic coordinates to rotation/translation-invariant contact descriptors
Dimensionality Reduction: Overcome the curse of dimensionality for clustering in high-dimensional spaces
State Identification: Determine the number and boundaries of conformational states
State Characterization: Identify which molecular interactions distinguish each state
A good review was written by Hanna Baltrukevich and Sabina Podlewska [8].
Test System
We analyze the Villin headpiece (PDB: 2RJY [1]), a 64-residue protein domain that serves often as a model system for protein folding studies [2-7]. The trajectory contains 9,368 frames (9368 ns) with 1,027 atoms.
The complete analysis requires 19 lines of code.
Import
We just need to import one thing. Just the PipelineManager. The whole analysis can be managed from here. We do not need other stuff.
Design note
Pipeline Builder Module
We use a builder pattern: the PipelineManager incrementally constructs an internal PipelineData structure.
Everything is centralized in
pipeline.dataand is enriched by the modules (trajectory, feature, feature_selector, decomposition, clustering, data_selector, comparison, feature_importance, plots).
mdxplain_root = "../"
data_path = "../data/2RJY/"
from mdxplain import PipelineManager
Methods
Step 1: Data Loading and Preprocessing
Efficient data handling is essential for processing large MD trajectories. Memory mapping allows analysis of datasets larger than available RAM by loading only required data sections. Residue labeling provides metadata necessary for interpreting structural features.
Note on memory mapping (memmap) and chunk sizing
What memmap is: Arrays are kept on disk and only the required slices are loaded into RAM on demand. This keeps the memory footprint low at the cost of extra I/O.
When to enable memmap (use_memmap=True):
Trajectories that approach/exceed available RAM
Multiple trajectories opened at once
Interactive analysis on laptops/workstations with limited memory
When to disable memmap (use_memmap=False):
Small/medium datasets that comfortably fit in RAM
You need maximum speed and have ample memory (e.g., HPC node)
You are on a slow or remote filesystem where frequent random I/O is costly
Choosing chunk_size (number of frames processed per batch):
Start with 500–2000 as a general rule of thumb; 1000 is a balanced default
Increase if you have plenty of RAM (fewer I/O operations, faster overall)
Decrease if you observe high memory usage, swapping, or OOM errors
Quick mental model for memory needs
Per-batch memory = (n_features × bytes_per_feature) × chunk_size_frames + overhead
Examples: contacts often use 1 byte/feature; float32 distances use 4 bytes/feature
Aim for the batch to stay well below ~50% of available RAM to leave room for temporary arrays and the OS
# Initialize pipeline and load trajectory data
pipeline = PipelineManager(use_memmap=True, chunk_size=1000, show_progress=False)
pipeline.trajectory.load_trajectories(data_input=str(data_path))
pipeline.trajectory.add_labels(
traj_selection="all"
)
📦 Creating Zarr cache: C:\Users\maxim\Documents\projects\mdxplain\tutorials\cache\cache_5b1c4ab6da4647679d92b485370c7c16_20260331_002204\2RJY_protein_simulation_run1_4fbff99a.dask.zarr
🔍 Analyzing trajectory dimensions...
📐 Trajectory: 10001 frames × 1027 atoms
💾 Writing trajectory data...
✅ Cache created: C:\Users\maxim\Documents\projects\mdxplain\tutorials\cache\cache_5b1c4ab6da4647679d92b485370c7c16_20260331_002204\2RJY_protein_simulation_run1_4fbff99a.dask.zarr
📊 Size: 89.0 MB
Loaded 1 systems with 1 total trajectories:
2RJY: 1 trajectories
pipeline.trajectory.print_info()
Loaded 1 trajectories:
[0] 2RJY_protein_simulation_run1: 10001 frames
Step 2: Feature Computation
Raw atomic coordinates are sensitive to molecular rotation and translation, making direct comparison between frames problematic. Pairwise residue distances and contacts provide rotation/translation-invariant descriptors that capture the essential physics of protein structure.
The distances default is a residue-residue metric. So all atom-atom distance between 2 residues are calculated and the closest heavy atom distance (without Hydrogen) is taken.
The contacts used here in the “contacts” feature is a static boolean value. So if the residue-residue distance is lower the threshold, the contact-value is true, else it is false. It is kind of a representation, if two residues interact with each other or not.
The 4.5 Å cutoff encompasses typical ranges for non-bonded interactions. It is a classical default, which is for example also used in mdciao [9] or MDAnalysis [10].
# Compute distance and contact features
pipeline.feature.add.distances()
pipeline.feature.add.contacts(cutoff=4.5)
Generated 1953 residue pairs for 64 residues
Step 3: Feature Selection
Why focus on contacts here
Interaction patterns can often reveal mechanistic differences between conformations more clearly than the magnitude of distance changes alone.
Contacts directly report formation/breaking of specific interactions, mapping naturally to hypotheses, mutational tests, and functional interpretation.
Therefore, in this tutorial we prioritize a contact-based analysis to highlight how interaction networks change across states.
# Create feature selector focused on contact analysis
# We create a selector and select the contacts of all available atoms / residues in this case
# After this step, we call select to create the feature-matrix in our pipeline
pipeline.feature_selector.create("contacts_only")
pipeline.feature_selector.add.contacts("contacts_only", "all")
pipeline.feature_selector.select("contacts_only")
Created feature selector: 'contacts_only'
Added to selector 'contacts_only': contacts -> 'all' (use_reduced=False, common_denominator=True, traj_selection=all, require_all_partners=False)
Applied feature selector 'contacts_only' with reference trajectory 0 successfully
Step 4: Dimensionality Reduction
The contact matrix contains (N² - N)/2 features (one per residue pair), creating a high-dimensional space where conventional clustering algorithms fail due to the “curse of dimensionality.” In high dimensions, all points become approximately equidistant, and noise dominates meaningful signals. Therefore we need to reduce the number of dimensions using a dimension reduction method.
A classical way doing this is a PCA [11], which tries to neglect correlative information, i.e. redundancy and catch the axis with the most variant linear combinations of features. Cause MD data are often non-linear, a kernel PCA [12] is the logical update to catch non-linear combinations of features.
Cause we are doing a contact analysis, it could make sense to build a principle component space based directly on this data. Therefore we are doing a contact kernel PCA.
This is basically a RBF kernel on the contact maps. This is equivalent to a hamming distance kernel. So we count the number of differences.
So the first component holds the non-linear dynamic motion with the biggest change in the interaction pattern of the protein, the second the 2nd biggest and so on, which is a good space to cluster conformational states.
Usually you can use the automatic value for n_components. It is using kneedle [19, 20] to find the elbow of the scree-plot and discard components not holding much informations. In this case, the example is a very short simulation of a small molecule, so there is not much dynamic. If we would take the 10-12 components defined by this metric, the cluster would appear very noisy or very small (i.e. we would have 14 clusters) and the result would not have the educational form we want to achive. So we just took the first 4 components to really focus on the most important dynamics and reduce the number of sharp clusters to just a few.
# Apply Contact Kernel PCA
pipeline.decomposition.add.contact_kernel_pca(
selection_name="contacts_only",
decomposition_name="ContactKPCA",
n_components=4,
force=True,
)
Starting eigendecomposition for 4 components...
Eigendecomposition completed after 21 matrix-vector products
Decomposition 'contact_kernel_pca' with name 'ContactKPCA' for selection 'contacts_only' computed successfully. Data reduced from (10001, 1953) to (10001, 4).
Step 5: Conformational State Identification
The goal of this step is to group the simulation trajectory data into a set of distinct conformational states using a clustering algorithm.
A primary challenge in this analysis is that conventional clustering methods, such as k-means, are problematic for this type of data. Such methods presuppose spherical cluster shapes and require the number of clusters to be known. Neither assumption is appropriate for the complex and unknown nature of conformational landscapes.
To address these limitations, we employ a density based clustering in this example the Density Peak Advanced (DPA) algorithm [13]. DPA identifies cluster centers as high-density regions that are separated by low-density boundaries, which allows it to automatically determine the optimal number of states. A Z-score(Z-value) threshold of 2.5 is used to achieve a balance between the sensitivity needed to resolve distinct conformational biases and the robustness required to filter out the thermal noise inherent to molecular dynamics simulations.
In our daily analysis of MD data, we find that DPA is not only highly effective but also more straightforward to apply than other density-based methods, such as DBSCAN or HDBSCAN. Its primary advantage lies in its practical approach to hyperparameter tuning. While the DPA algorithm includes several configurable parameters, we have found that in practice, default values are typically sufficient for the clustering of conformational states. The Z-value can the be used to control the desired level of clustering granularity. Higher Z-values produce a coarser clustering with fewer, more distinct states, while lower values yield a more fine-grained result. This provides us with an intuitive mechanism to adjust the clustering resolution, circumventing the need to optimize the more abstract hyperparameters, such as eps and min_samples, required by (H)DBSCAN.
# DPA clustering on decomposed data
pipeline.clustering.add.dpa(
"ContactKPCA",
Z=2.5,
cluster_name="DPA_ContactKPCA",
force=True,
)
Clustering 'DPA_ContactKPCA' completed successfully.
Found 4 clusters for 10001 frames.
Step 6: Temporal Dynamics - Cluster Membership Timeline
After identifying conformational states through clustering, a critical question arises: How do these states evolve over time? The membership plot visualizes cluster assignments across trajectory frames, revealing the temporal dynamics of conformational transitions.
This visualization addresses three key analytical needs:
Transition identification: When and how frequently does the system move between states?
State stability: How long does the system remain in each conformation?
Sampling quality: Have all identified states been adequately sampled?
Long continuous blocks of the same color indicate stable conformations, while frequent color changes suggest rapid interconversion or transitions through intermediate states. Black regions represent noise points that do not belong to any cluster.
fig = pipeline.plots.clustering.membership(
clustering_name="DPA_ContactKPCA",
save_fig=True,
file_format="svg",
tick_fontsize=18,
xlabel_fontsize=18,
ylabel_fontsize=18,
)
Figure saved to: C:\Users\maxim\Documents\projects\mdxplain\tutorials\cache\cache_5b1c4ab6da4647679d92b485370c7c16_20260331_002204\membership_DPA_ContactKPCA.svg

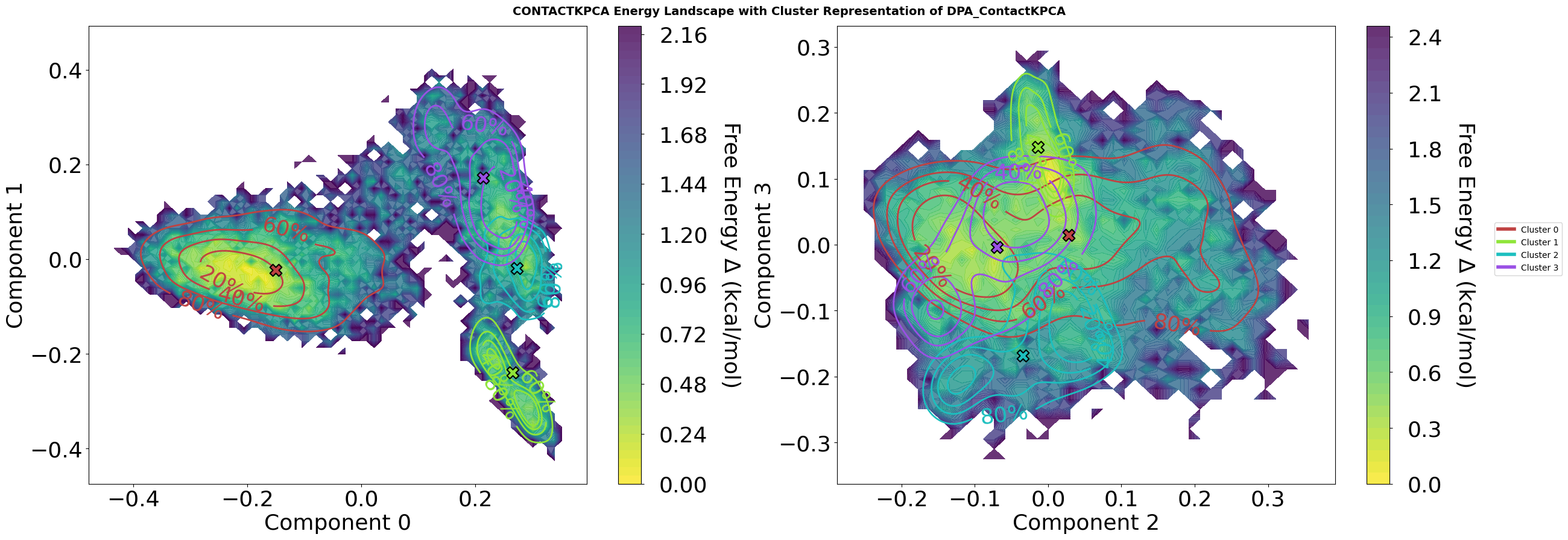
Step 7: Free Energy Landscape Visualization with Cluster Analysis
This visualization combines contact-based kernel PCA decomposition with density peak clustering to reveal the conformational landscape of the molecular dynamics trajectory.
Plot Features
Energy Landscape Background:
Calculated via Histogram or optional not standard Gaussian kernel density estimation (KDE) followed by optional Boltzmann inversion:
F = -kT. Pay attention. KDE can mask energy barriers. So Histograms are the real observations and therefor default. ln(P/P_max)Temperature set to 310.15 K (physiological body temperature)
Energy values in kcal/mol, with colormap ranging from low (blue) to high (red) energy states
Cluster Representation:
Density contours showing the conformational distribution of selected clusters (1, 2, 4, 5)
Contour lines labeled with percentiles (80%, 60%, 40%, 20%) indicating what fraction of cluster members lie within each boundary
Cluster centers marked with black-edged symbols showing the representative structure for each cluster
Colors are consistent across all plots, even when only specific clusters are displayed
Multi-Dimensional Projection:
Four-panel view showing projections on kernel PCA components: (0,1) and (2,3)
Each 2D projection reveals different aspects of the conformational space
KPC 0-1: Primary conformational motions captured by contact-based similarity
KPC 2-3: Secondary conformational variations orthogonal to main modes
Interpretation
The energy landscape reveals:
Deep basins (yellow) represent stable, frequently-sampled conformational states
Energy barriers (dark blue) separate different conformational basins
Cluster centers positioned in basin centers represent the a characteristic structures for each state
This combined view allows identification of:
Distinct conformational states (cluster centers in separate basins)
Transition pathways (saddle points between basins)
Conformational stability (basin depth and cluster density distribution)
State relationships (proximity of clusters in different projections)
Parameters
The plot method has a lot of different parameters to adjust the visualisation. Play a bit with them, to see what the module is capable of.
fig = pipeline.plots.landscape(
decomposition_name="ContactKPCA",
dimensions=[0, 1, 2, 3],
clustering_name="DPA_ContactKPCA",
save_fig=True,
file_format="svg",
tick_fontsize=26,
xlabel_fontsize=26,
ylabel_fontsize=26,
contour_label_fontsize=26,
)
Figure saved to: C:\Users\maxim\Documents\projects\mdxplain\tutorials\cache\cache_5b1c4ab6da4647679d92b485370c7c16_20260331_002204\landscape_ContactKPCA_dim0-1-2-3_DPA_ContactKPCA_centers_energy.svg
Step 8: Comparative Analysis Setup
Having identified conformational states, we now address the key biological question: which molecular interactions define each state?
Data selectors organize trajectory frames by cluster membership, enabling systematic comparison between states.
The one-vs-rest strategy identifies features that distinguish each state from all others, revealing the defining characteristics rather than just pairwise differences.
This approach provides a comprehensive molecular fingerprint for each conformational state.
pipeline.data_selector.create_from_clusters(
group_name="cluster",
clustering_name="DPA_ContactKPCA"
)
# Create one-vs-all comparison
pipeline.comparison.create_comparison(
name="cluster_comparison",
mode="one_vs_rest",
feature_selector="contacts_only",
data_selector_groups="cluster"
)
Step 9: Identifying Key Contacts with a Decision Tree
So, after we set up our “one-vs-rest” comparisons in Step 8. We now have to ask the question of, how do we actually find the molecular interactions that define each state? For this, we will use decision trees [14-16].
A decision tree is a great choice for this task because it creates a flowchart or tree of simple “yes/no” questions to classify the data. This is ideal for our purposes, cause tt works perfectly with our binary contact data (a contact is either formed or not) and is easy to interpret. It generates a set of human-readable rules that explain what makes a state unique.
A crucial point is, that we are not trying to build a perfect model to predict the state of new, unseen data, but use it as an explanatory tool. Our goal is to have the model describe the data we already have as accurately as possible.
We want it to tell us which contacts are the most important for distinguishing the conformational states we’ve found. Therefore, the traditional concern about “overfitting” doesn’t apply here, cause we are interested in the features that define our specific dataset.
# Analyze feature importance
pipeline.feature_importance.add.decision_tree(
comparison_name="cluster_comparison",
analysis_name="feature_importance"
)
The decision_trees() plot provides a visual representation of the classification rules the model learned. Each tree corresponds to one
comparison (e.g., “State A vs all other states”).
Reading the visualization:
Boxes (nodes) show the decision criteria and class statistics at each step
Edges (arrows) show the conditions (e.g., “Contact” or “≤ 3.50 Å”) that lead to each branch
Red boxes highlight the most decisive nodes for identifying a state
Path from top to bottom shows the sequence of questions asked to classify a conformation
We set short_edge_labels=True to display only the condition values on the edges (e.g., “Contact” instead of “contacts: Leu13-ARG31 =
Contact”), making the tree easier to read. The separate_trees=True parameter plots each comparison tree as an individual figure instead of a
grid layout, which is especially useful for deeper trees (depth 5-6) where individual trees need more space for clarity. The max_depth_display=3 parameter limits the visualization to the first three decision levels,
focusing on the most important interactions.
The resulting trees reveal which specific molecular contacts are critical for defining each conformational state, providing actionable insights for understanding your system’s dynamics.
fig = pipeline.plots.feature_importance.decision_trees(
feature_importance_name="feature_importance",
save_fig=True,
short_layout=True,
hide_path=False,
separate_trees=True,
width_scale_factor=0.4,
height_scale_factor=0.5,
edge_symbol_fontsize=18,
file_format="svg"
)
ℹ️ Creating 4 separate trees (depth=3, comparisons=4)
Saved: C:\Users\maxim\Documents\projects\mdxplain\tutorials\cache\cache_5b1c4ab6da4647679d92b485370c7c16_20260331_002204\decision_trees_feature_importance_comparison_00_cluster_0_vs_rest.svg

Saved: C:\Users\maxim\Documents\projects\mdxplain\tutorials\cache\cache_5b1c4ab6da4647679d92b485370c7c16_20260331_002204\decision_trees_feature_importance_comparison_01_cluster_1_vs_rest.svg

Saved: C:\Users\maxim\Documents\projects\mdxplain\tutorials\cache\cache_5b1c4ab6da4647679d92b485370c7c16_20260331_002204\decision_trees_feature_importance_comparison_02_cluster_2_vs_rest.svg

Saved: C:\Users\maxim\Documents\projects\mdxplain\tutorials\cache\cache_5b1c4ab6da4647679d92b485370c7c16_20260331_002204\decision_trees_feature_importance_comparison_03_cluster_3_vs_rest.svg

4 tree figures saved successfully
Step 10: Identifying the Top Contacts
The decision tree analysis provides a feature importance score for every contact. scikit-learn [16] calculates this value as the Gini Importance or the Entropy, depending on which criterion was used to create the trees. Default is gini.
This score measures how effective a contact is at creating “purer” decision nodes in the tree. In other words, how well it helps to cleanly separate one state from all the others.
These scores are normalized to a range between 0.0 and 1.0. A higher score means more important feature in the fingerprint of this cluster.
To focus on the most essential information, we select the 3 contacts with the highest feature importance scores. These few contacts represent the core of the fingerprint for that state.
pipeline.feature_importance.print_top_n_features(
analysis_name="feature_importance"
)
Top 3 features for cluster_0_vs_rest:
1. contacts: ALA25-LEU29: Non Contact (0.936)
2. contacts: ALA25-ASP28: Non Contact (0.034)
3. contacts: THR24-PRO30: Non Contact (0.030)
Top 3 features for cluster_1_vs_rest:
1. contacts: PRO30-HIS41: Non Contact (0.918)
2. contacts: PHE16-VAL33: Non Contact (0.041)
3. contacts: GLU27-ARG31: Non Contact (0.033)
Top 3 features for cluster_2_vs_rest:
1. contacts: PRO35-LYS38: Non Contact (0.485)
2. contacts: PRO17-SER43: Non Contact (0.325)
3. contacts: LEU13-ARG31: Non Contact (0.059)
Top 3 features for cluster_3_vs_rest:
1. contacts: PRO35-LYS38: Non Contact (0.591)
2. contacts: PRO17-SER43: Non Contact (0.194)
3. contacts: THR24-LEU29: Non Contact (0.125)
pipeline.data.feature_importance_data["feature_importance"]
FeatureImportanceData(name='feature_importance', analyzer='decision_tree', n_comp=4)
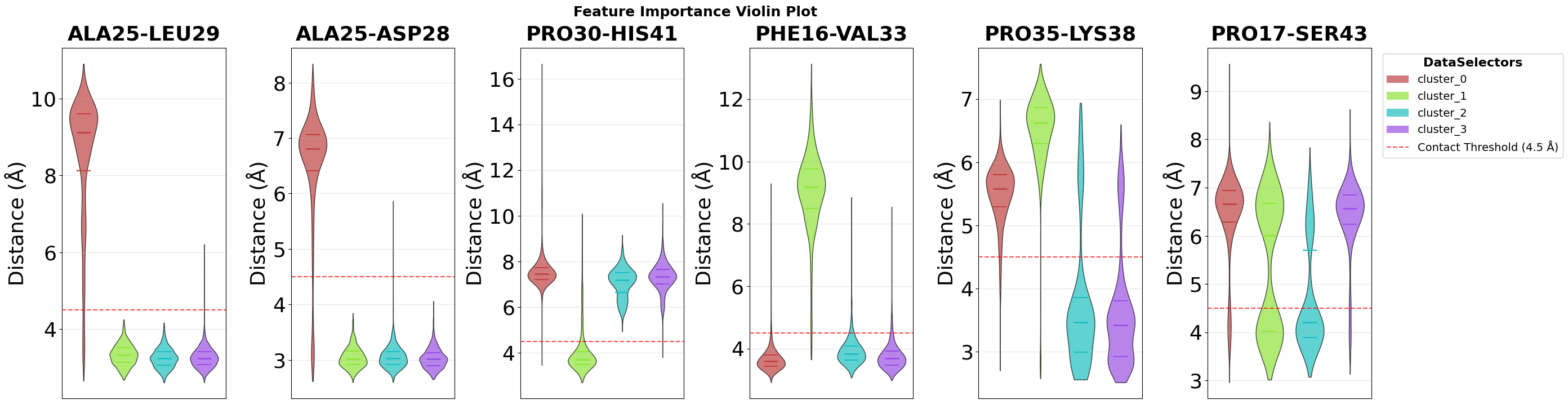
Violin Plot Visualisation
The feature importance analysis identifies which structural features best distinguish individual clusters. To visualize the distribution of these top features across all clusters, we use violin plots, which show not only mean values but the complete distribution of feature values in each cluster.
Each violin combines a box plot (showing median and quartiles) with a kernel density estimate (the width), revealing both central tendency and the full shape of the feature value distribution in each cluster.
fig = pipeline.plots.feature_importance.violins(
feature_importance_name="feature_importance",
n_top=2,
save_fig=True,
max_cols=7,
file_format="svg",
tick_fontsize=26,
ylabel_fontsize=26,
subplot_title_fontsize=26,
)
Figure saved: C:\Users\maxim\Documents\projects\mdxplain\tutorials\cache\cache_5b1c4ab6da4647679d92b485370c7c16_20260331_002204\violin_feature_importance_top2.svg
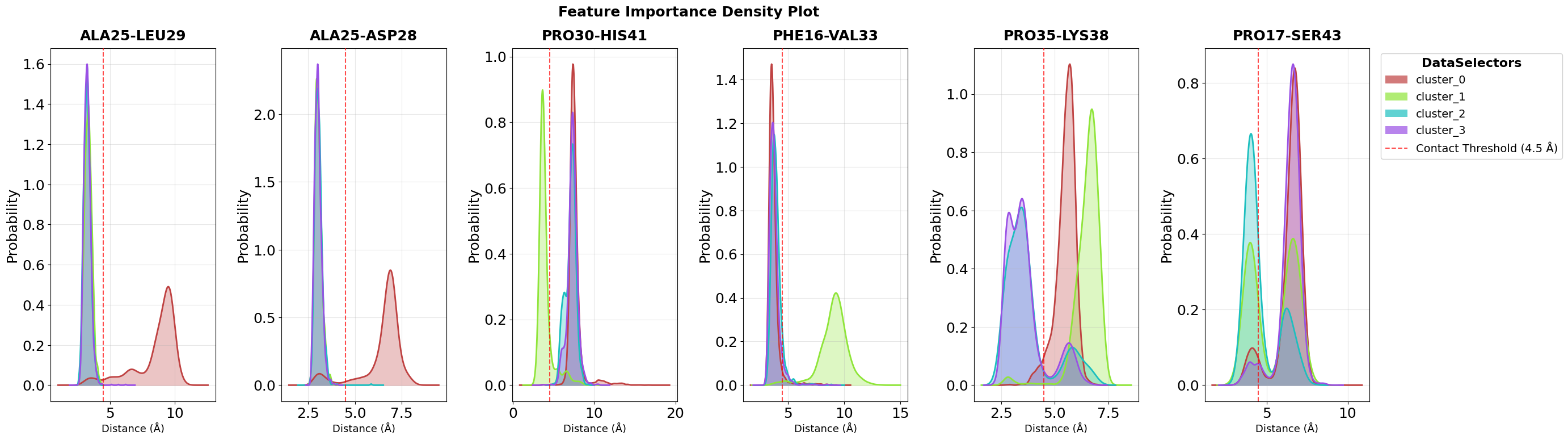
Density Plot Visualisation
While violin plots show the complete distribution within each cluster, density plots provide a complementary view by overlaying the probability density curves of all clusters in a single panel per feature. This makes it easier to directly compare how feature values differ between clusters.
Each colored curve represents one cluster’s distribution, and the height of the curve at any point indicates the probability density of that feature value. Where curves separate clearly, we see strong discriminatory power. These are the features that effectively distinguish between conformational states.
The n_top=2 parameter focuses on the two most important features identified by the decision tree analysis, while max_cols=7 controls the
grid layout for multi-feature visualizations.
fig = pipeline.plots.feature_importance.densities(
feature_importance_name="feature_importance",
n_top=2,
save_fig=True,
max_cols=7,
file_format="svg",
tick_fontsize=18,
ylabel_fontsize=18,
subplot_title_fontsize=18,
)
Figure saved: C:\Users\maxim\Documents\projects\mdxplain\tutorials\cache\cache_5b1c4ab6da4647679d92b485370c7c16_20260331_002204\density_feature_importance_top2.svg
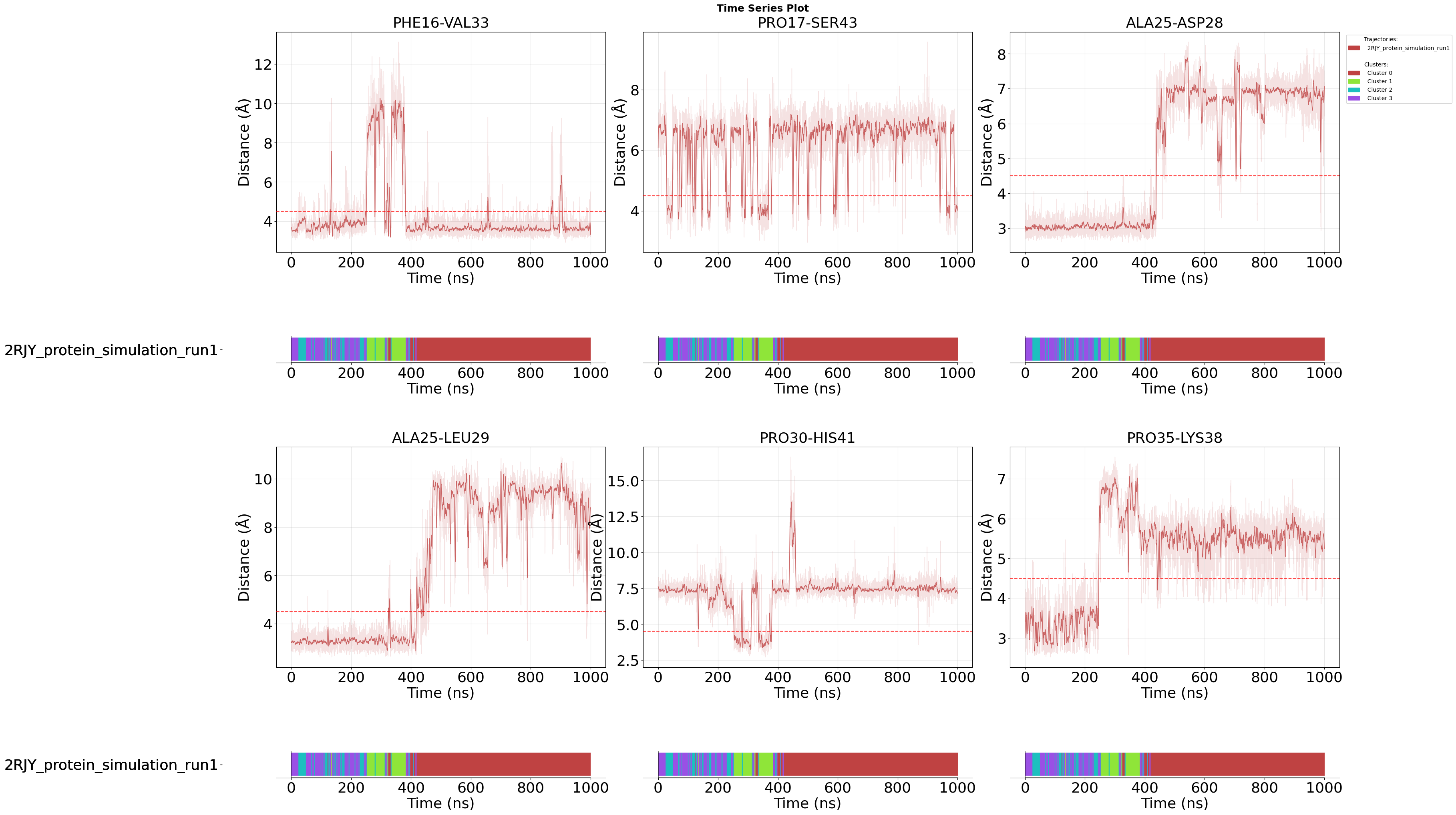
Time Series Visualisation
After examining the statistical distributions of important features across clusters (violin and density plots), time series plots reveal how these features evolve over the course of the simulation. This temporal perspective helps identify when and how transitions between conformational states occur.
Each plot shows the feature values over simulation time, with the membership_per_feature=True parameter adding a color-coded bar under each feature, that indicates cluster assignment at each frame. This allows you to directly correlate feature value changes with state transitions.
Setting this to False would instead show a single membership plot for all features combined, which is useful when you want to focus purely on feature evolution without per-feature state annotations.
For example, you can observe whether a specific contact forms gradually or abruptly when the system transitions from one cluster to another.
The clustering_name parameter specifies which clustering result to use for the membership visualization, enabling analysis of how different
clustering methods capture the dynamics.
fig = pipeline.plots.feature_importance.time_series(
feature_importance_name="feature_importance",
n_top=2,
save_fig=True,
max_cols=3,
membership_per_feature=True,
clustering_name="DPA_ContactKPCA",
file_format="svg",
tick_fontsize=26,
ylabel_fontsize=26,
xlabel_fontsize=26,
subplot_title_fontsize=26,
)
Loading time data...
Figure saved: C:\Users\maxim\Documents\projects\mdxplain\tutorials\cache\cache_5b1c4ab6da4647679d92b485370c7c16_20260331_002204\time_series_feature_importance_top2.svg
Step 11: Structural Visualization of Feature Importance
After identifying the most important molecular contacts through decision tree analysis, the next step is to visualize these features directly on the protein structure. This spatial perspective helps understand where in the 3D structure the critical interactions occur and how they relate to the overall protein architecture.
The workflow consists of two steps: First, we create modified PDB files where feature importance scores are encoded in the B-factor column. Then, we visualize these PDB files either using PyMOL [17] or NGLView [18] (for interactive exploration in Jupyter).
11.1 Creating PDB Files with Feature Importance Encoding
The create_pdb_with_beta_factors() method creates modified PDB files where feature importance scores are encoded in the B-factor column. Each residue’s B-factor is replaced with a importance score of its most relevant feature (e.g., the most important contact involving that residue).
How the mapping works: For each top feature (e.g., contact “Leu13-ARG31” with importance score 0.85), all participating residues (Leu13 and ARG31) receive that feature’s importance score. If a residue appears in multiple important features, the scores are summed (not averaged). For example, if Leu13 appears in three top features with scores 0.85, 0.60, and 0.45, its total importance becomes 1.90. After summation, the scores are normalized to a 0-1 range by dividing by the maximum score, where 1.0 represents the residue with the highest accumulated importance across all features. All atoms within a residue receive the same B-factor value, as importance is calculated at the residue level.
This B-factor encoding is a widely supported standard that allows any molecular visualization software to color the structure by importance using standard B-factor coloring schemes. The method creates one PDB file per cluster, all stored in the cache directory for subsequent visualization.
pipeline.structure_visualization.feature_importance.create_pdb_with_beta_factors(
structure_viz_name="structure_viz",
feature_importance_name="feature_importance",
)
11.2 PyMOL Visualization
The create_pymol_script() method generates a ready-to-use PyMOL script that automatically loads the PDB files created in the previous step and applies sophisticated coloring based on feature importance scores.
The script handles all visualization details, including color gradients, transparency, and highlighting of important residues. The feature_own_color=False parameter uses a unified color scheme across all features, making it easier to compare importance across different regions.
Two Group Types for Flexible Analysis:
Single Comparison Group (disabled by default): Shows all sub-comparisons side-by-side, with each structure aligned to the first. Each structure displays its own features as stick representations. This view is ideal for direct structural comparison across all sub-comparisons simultaneously.
Focus Groups (first enabled by default): Creates one group per sub-comparison (e.g., “all_focus_struct_cluster_0_vs_rest”). Each group shows its own structure with full opacity while displaying all other structures at 80% transparency as context. This allows you to focus on one comparison at a time while maintaining spatial context from others.
The key advantage of this group-based approach is that you can toggle individual components (structures, features) on and off within each group in the PyMOL GUI, giving you full control over what to display.
Important Note for Jupyter Notebooks: PyMOL can have compatibility issues when launched directly from Jupyter notebooks. For notebook-based workflows, we recommend using NGLView (see section 11.3) or manually opening the generated script in PyMOL. For Python scripts, you can use pipeline.structure_visualization.feature_importance.visualize_pymol() to launch PyMOL directly.
pipeline.structure_visualization.feature_importance.create_pymol_script(
structure_viz_name="structure_viz"
)
'C:\\Users\\maxim\\Documents\\projects\\mdxplain\\tutorials\\cache\\cache_5b1c4ab6da4647679d92b485370c7c16_20260331_002204\\structure_viz\\structure_viz.pml'
11.3 Interactive Jupyter Visualization with NGLView
The visualize_nglview_jupyter() method creates an interactive 3D visualization directly in your Jupyter notebook using the PDB files created earlier. This provides immediate visual feedback without leaving your analysis environment.
The interactive viewer allows you to rotate, zoom, and inspect the structure in real-time. Feature importance scores are color-mapped onto the structure via the B-factor values, and a legend explains the color gradient. Additional controls (download button, structure legend) help you save and document your visualizations.
This method is ideal for exploratory analysis and rapid iteration during the analysis workflow.
ui, view = pipeline.structure_visualization.feature_importance.visualize_nglview_jupyter(
structure_viz_name="structure_viz",
)
Step 12: Saving and loading the pipeline
In mdxplain you can save a whole pipeline with all your data and calculations and load it later again. Just do the following.
pipeline.save_to_single_file("cache/example_pipeline.pkl")
loaded_pipeline = PipelineManager.load_from_single_file("cache/example_pipeline.pkl")
Resource limits applied: cpu_affinity=12 cores, nice=15, io_priority=low, blas_threads=12
You can also work with shareable archives, which is bigger in space but shares all necessary stuff.
pipeline.create_sharable_archive("cache/example_pipeline.tar.zst", overwrite=True)
Adding files to archive: 100%|██████████| 21/21 [00:00<00:00, 66.87file/s]
'C:\\Users\\maxim\\Documents\\projects\\mdxplain\\tutorials\\cache\\example_pipeline.tar.zst'
loaded_pipeline_archive = PipelineManager.load_from_archive("cache/example_pipeline.tar.zst", sha="cache/example_pipeline.tar.zst.sha")
Resource limits applied: cpu_affinity=10 cores, nice=15, io_priority=low, blas_threads=10
Step 13: Info Printing
With print_info() you can get a lot of informations about the content of your pipeline. After or before the loading. To know, whats in there.
loaded_pipeline.print_info()
======= PIPELINE INFORMATION =======
--- Trajectory Data ---
Loaded 1 trajectories:
[0] 2RJY_protein_simulation_run1: 10001 frames
--- Feature Data ---
=== Feature Information ===
Feature Types: 2 (distances, contacts)
--- distances ---
Trajectory 0:
=== FeatureData ===
Feature Type: Distances
Original Data: 10001 frames x 1953 features
Feature Metadata: 1953 feature definitions
--- contacts ---
Trajectory 0:
=== FeatureData ===
Feature Type: Contacts
Original Data: 10001 frames x 1953 features
Feature Metadata: 1953 feature definitions
--- Feature Selection Data ---
=== FeatureSelectorData Information ===
FeatureSelectorData Names: 1 (contacts_only)
--- contacts_only ---
=== FeatureSelectorData ===
Name: contacts_only
Feature Types: 1 (contacts)
Total Selections: 1
Reference Trajectory: 0
Matrix Columns: 1953
Selection Results: Available for 1 feature types (contacts)
--- Clustering Data ---
=== ClusteringData Information ===
ClusteringData Names: 1 (DPA_ContactKPCA)
--- DPA_ContactKPCA ---
=== ClusterData ===
Cluster Type: DPA
Number of Clusters: 4
Number of Frames: 10001
Hyperparameters: Z=2.5, metric=euclidean, affinity=nearest_neighbors, density_algo=PAk, k_max=1000, D_thr=23.92812698, dim_algo=twoNN, blockAn=True, block_ratio=20, frac=1.0, halos=False, method=standard, sample_size=10000, knn_neighbors=5, force=True, n_jobs=-1
Frame Mapping: 10001 frames from 1 trajectories
--- Decomposition Data ---
=== DecompositionData Information ===
DecompositionData Names: 1 (ContactKPCA)
--- ContactKPCA ---
=== DecompositionData ===
Decomposition Type: CONTACT_KERNEL_PCA
Transformed Data: 10001 frames x 4 components
Hyperparameters: n_components=4, kernel=rbf, gamma=0.046641666273688154, use_nystrom=False, n_landmarks=2000, landmark_selection_mode=kmeans, random_state=None, auto_select=False, offset=0, kernel_description=rbf on binary data (Hamming distance), contact_kernel=True, binary_data=True
Frame Mapping: 10001 frames from 1 trajectories
--- Data Selector Data ---
=== DataSelectorData Information ===
DataSelectorData Names: 4 (cluster_0, cluster_1, cluster_2, cluster_3)
--- cluster_0 ---
=== DataSelectorData ===
Name: cluster_0
Selected Frames: 6062 frames from 1 trajectories
Selection Type: cluster
Frame Distribution: traj0:73-10000 (6062)
--- cluster_1 ---
=== DataSelectorData ===
Name: cluster_1
Selected Frames: 1077 frames from 1 trajectories
Selection Type: cluster
Frame Distribution: traj0:481-3821 (1077)
--- cluster_2 ---
=== DataSelectorData ===
Name: cluster_2
Selected Frames: 958 frames from 1 trajectories
Selection Type: cluster
Frame Distribution: traj0:5-9874 (958)
--- cluster_3 ---
=== DataSelectorData ===
Name: cluster_3
Selected Frames: 1904 frames from 1 trajectories
Selection Type: cluster
Frame Distribution: traj0:0-4359 (1904)
--- Comparison Data ---
=== Comparison Information ===
Comparison Names: 1 (cluster_comparison)
--- cluster_comparison ---
=== ComparisonData ===
Name: cluster_comparison
Comparison Mode: one_vs_rest
Feature Selector: contacts_only
Data Selectors: 4 (cluster_0, cluster_1, cluster_2, cluster_3)
Sub-Comparisons: 4 (cluster_0_vs_rest, cluster_1_vs_rest, cluster_2_vs_rest, cluster_3_vs_rest)
--- Feature Importance Data ---
=== FeatureImportanceData Information ===
FeatureImportanceData Names: 1 (feature_importance)
--- feature_importance ---
=== FeatureImportanceData ===
Name: feature_importance
Analyzer Type: decision_tree
Comparison: cluster_comparison
Sub-Comparisons: 4 (cluster_0_vs_rest, cluster_1_vs_rest, cluster_2_vs_rest, cluster_3_vs_rest)
Features Analyzed: 1953
Top Feature Overall: PRO35-LYS38 (avg importance: 0.2690)
Top 3 Features: PRO35-LYS38 (0.269), ALA25-LEU29 (0.248), PRO30-HIS41 (0.230)
======= END PIPELINE INFORMATION =======
Pipeline Summary: 1 trajectories, 2 feature types, 1 feature selections, 1 clusterings, 1 decompositions, 4 data selectors, 1 comparisons, 1 feature importance analyses, 0 custom metadata entries
loaded_pipeline_archive.print_info()
======= PIPELINE INFORMATION =======
--- Trajectory Data ---
Loaded 1 trajectories:
[0] 2RJY_protein_simulation_run1: 10001 frames
--- Feature Data ---
=== Feature Information ===
Feature Types: 2 (distances, contacts)
--- distances ---
Trajectory 0:
=== FeatureData ===
Feature Type: Distances
Original Data: 10001 frames x 1953 features
Feature Metadata: 1953 feature definitions
--- contacts ---
Trajectory 0:
=== FeatureData ===
Feature Type: Contacts
Original Data: 10001 frames x 1953 features
Feature Metadata: 1953 feature definitions
--- Feature Selection Data ---
=== FeatureSelectorData Information ===
FeatureSelectorData Names: 1 (contacts_only)
--- contacts_only ---
=== FeatureSelectorData ===
Name: contacts_only
Feature Types: 1 (contacts)
Total Selections: 1
Reference Trajectory: 0
Matrix Columns: 1953
Selection Results: Available for 1 feature types (contacts)
--- Clustering Data ---
=== ClusteringData Information ===
ClusteringData Names: 1 (DPA_ContactKPCA)
--- DPA_ContactKPCA ---
=== ClusterData ===
Cluster Type: DPA
Number of Clusters: 4
Number of Frames: 10001
Hyperparameters: Z=2.5, metric=euclidean, affinity=nearest_neighbors, density_algo=PAk, k_max=1000, D_thr=23.92812698, dim_algo=twoNN, blockAn=True, block_ratio=20, frac=1.0, halos=False, method=standard, sample_size=10000, knn_neighbors=5, force=True, n_jobs=-1
Frame Mapping: 10001 frames from 1 trajectories
--- Decomposition Data ---
=== DecompositionData Information ===
DecompositionData Names: 1 (ContactKPCA)
--- ContactKPCA ---
=== DecompositionData ===
Decomposition Type: CONTACT_KERNEL_PCA
Transformed Data: 10001 frames x 4 components
Hyperparameters: n_components=4, kernel=rbf, gamma=0.046641666273688154, use_nystrom=False, n_landmarks=2000, landmark_selection_mode=kmeans, random_state=None, auto_select=False, offset=0, kernel_description=rbf on binary data (Hamming distance), contact_kernel=True, binary_data=True
Frame Mapping: 10001 frames from 1 trajectories
--- Data Selector Data ---
=== DataSelectorData Information ===
DataSelectorData Names: 4 (cluster_0, cluster_1, cluster_2, cluster_3)
--- cluster_0 ---
=== DataSelectorData ===
Name: cluster_0
Selected Frames: 6062 frames from 1 trajectories
Selection Type: cluster
Frame Distribution: traj0:73-10000 (6062)
--- cluster_1 ---
=== DataSelectorData ===
Name: cluster_1
Selected Frames: 1077 frames from 1 trajectories
Selection Type: cluster
Frame Distribution: traj0:481-3821 (1077)
--- cluster_2 ---
=== DataSelectorData ===
Name: cluster_2
Selected Frames: 958 frames from 1 trajectories
Selection Type: cluster
Frame Distribution: traj0:5-9874 (958)
--- cluster_3 ---
=== DataSelectorData ===
Name: cluster_3
Selected Frames: 1904 frames from 1 trajectories
Selection Type: cluster
Frame Distribution: traj0:0-4359 (1904)
--- Comparison Data ---
=== Comparison Information ===
Comparison Names: 1 (cluster_comparison)
--- cluster_comparison ---
=== ComparisonData ===
Name: cluster_comparison
Comparison Mode: one_vs_rest
Feature Selector: contacts_only
Data Selectors: 4 (cluster_0, cluster_1, cluster_2, cluster_3)
Sub-Comparisons: 4 (cluster_0_vs_rest, cluster_1_vs_rest, cluster_2_vs_rest, cluster_3_vs_rest)
--- Feature Importance Data ---
=== FeatureImportanceData Information ===
FeatureImportanceData Names: 1 (feature_importance)
--- feature_importance ---
=== FeatureImportanceData ===
Name: feature_importance
Analyzer Type: decision_tree
Comparison: cluster_comparison
Sub-Comparisons: 4 (cluster_0_vs_rest, cluster_1_vs_rest, cluster_2_vs_rest, cluster_3_vs_rest)
Features Analyzed: 1953
Top Feature Overall: PRO35-LYS38 (avg importance: 0.2690)
Top 3 Features: PRO35-LYS38 (0.269), ALA25-LEU29 (0.248), PRO30-HIS41 (0.230)
======= END PIPELINE INFORMATION =======
Pipeline Summary: 1 trajectories, 2 feature types, 1 feature selections, 1 clusterings, 1 decompositions, 4 data selectors, 1 comparisons, 1 feature importance analyses, 0 custom metadata entries
Discussion
This tutorial walked through an end‑to‑end, contact‑focused workflow: Feature engineering of residue contacts, dimensionality reduction with Contact Kernel PCA, and clustering with DPA, to identify conformational states and the specific interactions that define them.
The key strength of mdxplain is its modular pipeline builder: each step can be swapped or extended without changing the overall flow, and all intermediate results are collected and reused via pipeline.data.
Beyond the minimal example, mdxplain supports a broader feature set (e.g., DSSP/secondary structure, torsion angles, SASA, distances, raw coordinates) and multiple alternatives for dimensionality reduction and clustering.
By standardizing data flow and bookkeeping, the library streamlines building and saving analyses.
Common applications include:
Exporting feature matrices for downstream machine‑learning models.
Tag‑based comparisons across conditions (e.g., wild type vs mutant, ligand‑bound vs apo) to identify discriminative features (contacts, secondary structure, SASA) and explain structural/dynamical effects.
Estimating state transition counts and preparing inputs for Markov state models.
Computing contact frequencies or other statistical feature properties and their differences across systems.
Doing RMSD and RMSF analysis for basic insights into the systems.
Paralell working on many trajectories at once.
Having many different metrices and features of many different trajectories at one place.
And many more.
To extend the workflow, pipeline.analysis.structure provides multiple RMSD/RMSF metrics, and pipeline.analysis.feature.* offers per‑feature statistics (e.g., contact frequencies, transition counts). Combining these with state discovery enables richer, multi‑faceted analyses that connect structure, dynamics, and feature statistics.
Limitations and outlook
The quality of any analysis depends on adequate conformational sampling and the suitability of the chosen descriptors. Hyperparameters such as contact cutoffs, the number of components, and clustering sensitivity may require light tuning across systems.
Also the clustering accuracy influences the process. Noisy clusters leads to problems in the classification process.
Also there are thousands of different other methods one could use for the analysis. But for this cases, mdxplain serves you with the necessary feature-data in an memory efficient, performant and streamlined way.
But with this, there is another limitation. Disk space. If you use your disk for big analysis, cause your trajectory and feature data does not fit in RAM, you need disk space. For hugh system this can also become a problem.
Conclusion
mdxplain lowers the effort to move from raw trajectories to interpretable, testable insights by simplifying the composition, execution, and persistence of complex structural analysis pipelines. Its modular design and extensibility make it a practical tool across structural biology use cases.
References
[1] Crystal Structure of a pH-Stabilized Mutant of Villin Headpiece, Jianmin Meng and C. James McKnight, Biochemistry 2008 47 (16), 4644-4650, DOI: 10.1021/bi7022738
[2] ROCKLIN, Gabriel J., et al. Global analysis of protein folding using massively parallel design, synthesis, and testing. Science, 2017, 357. Jg., Nr. 6347, S. 168-175.
[3] Melvin RL, Godwin RC, Xiao J, Thompson WG, Berenhaut KS, Salsbury FR Jr. Uncovering Large-Scale Conformational Change in Molecular Dynamics without Prior Knowledge. J Chem Theory Comput. 2016 Dec 13;12(12):6130-6146. doi: 10.1021/acs.jctc.6b00757
[4] H. Lei,C. Wu,H. Liu, & Y. Duan, Folding free-energy landscape of villin headpiece subdomain from molecular dynamics simulations, Proc. Natl. Acad. Sci. U.S.A. 104 (12) 4925-4930, https://doi.org/10.1073/pnas.0608432104 (2007).
[5] Ensign DL, Kasson PM, Pande VS. Heterogeneity even at the speed limit of folding: large-scale molecular dynamics study of a fast-folding variant of the villin headpiece. J Mol Biol. 2007 Nov 30;374(3):806-16. doi: 10.1016/j.jmb.2007.09.069. Epub 2007 Sep 29. Erratum in: J Mol Biol. 2008 Nov 21;383(4):935. PMID: 17950314; PMCID: PMC3689540.
[6] Roy González-Alemán, Daniel Platero-Rochart, David Hernández-Castillo, Erix W Hernández-Rodríguez, Julio Caballero, Fabrice Leclerc, Luis Montero-Cabrera, BitQT: a graph-based approach to the quality threshold clustering of molecular dynamics, Bioinformatics, Volume 38, Issue 1, January 2022, Pages 73–79, https://doi.org/10.1093/bioinformatics/btab595
[7] WANG, Ercheng, et al. A novel folding pathway of the villin headpiece subdomain HP35. Physical Chemistry Chemical Physics, 2019, 21. Jg., Nr. 33, S. 18219-18226.
[8] Baltrukevich, Hanna, and Sabina Podlewska. “From data to knowledge: systematic review of tools for automatic analysis of molecular dynamics output.” Frontiers in Pharmacology 13 (2022): 844293.
[9] Pérez-Hernández, Guillermo, and Peter W. Hildebrand. “Mdciao: accessible analysis and visualization of molecular dynamics simulation data.” PLOS Computational Biology 21.4 (2025): e1012837.
[10] Michaud‐Agrawal, Naveen, et al. “MDAnalysis: a toolkit for the analysis of molecular dynamics simulations.” Journal of computational chemistry 32.10 (2011): 2319-2327.
[11] David, Charles C., and Donald J. Jacobs. “Principal component analysis: a method for determining the essential dynamics of proteins.” Protein dynamics: Methods and protocols. Totowa, NJ: Humana Press, 2013. 193-226.
[12] Schölkopf, Bernhard, Alexander Smola, and Klaus-Robert Müller. “Kernel principal component analysis.” International conference on artificial neural networks. Berlin, Heidelberg: Springer Berlin Heidelberg, 1997.
[13] d’Errico, Maria, et al. “Automatic topography of high-dimensional data sets by non-parametric density peak clustering.” Information Sciences 560 (2021): 476-492.
[14] Breiman, Leo, et al. Classification and regression trees. Chapman and Hall/CRC, 2017.
[15] Quinlan, J. Ross. “Induction of decision trees.” Machine learning 1.1 (1986): 81-106.
[16] Pedregosa, Fabian, et al. “Scikit-learn: Machine learning in Python.” the Journal of machine Learning research 12 (2011): 2825-2830.
[17] DeLano, Warren L. “Pymol: An open-source molecular graphics tool.” CCP4 Newsl. protein crystallogr 40.1 (2002): 82-92.
[18] Rose, Alexander S., and Peter W. Hildebrand. “NGL Viewer: a web application for molecular visualization.” Nucleic acids research 43.W1 (2015): W576-W579.
[19] Satopaa, Ville, et al. “Finding a” kneedle” in a haystack: Detecting knee points in system behavior.” 2011 31st international conference on distributed computing systems workshops. IEEE, 2011.
[20] Cattell, Raymond B. “The scree test for the number of factors.” Multivariate behavioral research 1.2 (1966): 245-276.
AI Disclaimer
This notebook was written with the suppport of Github Copilot with OpenAI GPT-5 and Google Gemini 2.5 Pro